小课堂,关联查询时进行条件过滤
-
下面是一个简单场景的ER图,来源于PostgREST,该场景描述了电影、导演、演员、角色、技术、提名、竞争对手等表之间的关联关系:
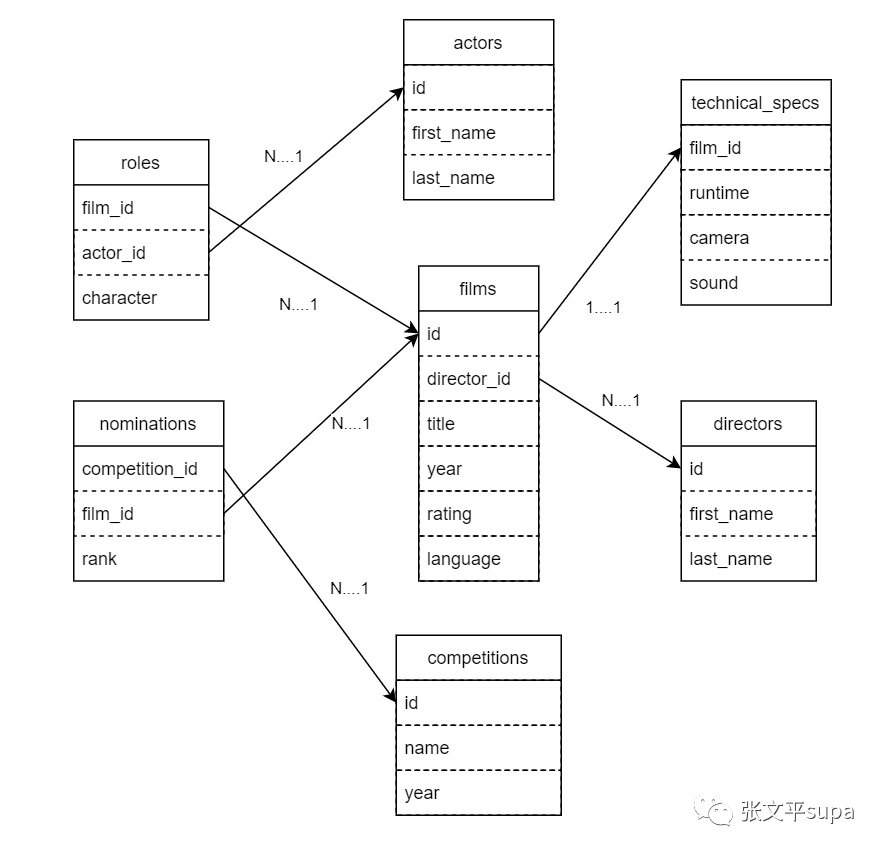
create table directors( id serial primary key, first_name text, last_name text ); create table films( id serial primary key, director_id int references directors(id), title text, year int, rating numeric(3,1), language text ); create table actors( id serial primary key, first_name text, last_name text ); create table roles( film_id int references films(id), actor_id int references actors(id), character text, primary key(film_id, actor_id) ); CREATE TABLE technical_specs( film_id INT REFERENCES films UNIQUE, runtime TIME, camera TEXT, sound TEXT );我们可以在关联查询时附加额外的where条件进行数据过滤,也可以进行排序操作。
1.1 排序
// 按actors.last_name升序排序 const { data, error } = await supabase .from('films') .select(`*, actors(*)`) .order('actors.last_name') // 按actors.last_name降序排序 const { data, error } = await supabase .from('films') .select(`*, actors(*)`) .order('actors.last_name', { ascending: false }) // 按actors.last_name降序排序, first_name升序 const { data, error } = await supabase .from('films') .select(`*, actors(*)`) .order('actors.last_name', { ascending: false }) .order('actors.first_name')1.2过滤
supabase支持绝大部分过滤条件,过滤条件要写在select函数调用之后,举例如下:
// in 条件 const { data, error } = await supabase .from('films') .select(`*, roles(*)`) .in('roles.character', ['Chico','Harpo','Groucho']) // or 条件 const { data, error } = await supabase .from('films') .select(`*, roles(*)`) .or('roles.character.in.(Chico,Harpo,Groucho)', 'roles.character.eq.Zeppo')更多的过滤条件的用法可以参考官方文档。
1.3 limit
限制返回数据的条数:
const { data, error } = await supabase .from('films') .select(`*, roles(*)`) .limit(10)分页查询:
// 前10条 const { data, error } = await supabase .from('films') .select(`*, roles(*)`) .range(0, 9) // 第10条到19条(共10条) const { data, error } = await supabase .from('films') .select(`*, roles(*)`) .range(10, 19)