小课堂,没有外键关系的两个表进行关联查询
-
有的时候,我们没有办法在两个表之间建立外键关联,可能是因为历史原因,也可能是技术上不可行(比如FDW表),但业务上又需要在两个表之间进行关联查询,这时候怎么办呢。此时可以通过 function 手动建立关联关系。
1.1 如何使用function
假设我们有一个表是从csv文件中导入的,建表语句如下:
create foreign table premieres ( id integer, location text, "date" date, film_id integer ) server import_csv options ( filename '/tmp/directors.csv', format 'csv');为了在 premieres 和 films 表之间建立关联关系,从而允许开发人员通过supabase SDK对这两个表进行关联查询,我们可以创建如下 function :
create function film(premieres) returns setof films rows 1 as $$ select * from films where id = $1.film_id $$ stable language sql;该 function 的输入参数是表 premieres ,返回结果是表 films ,关联条件是:
select * from films where id = $1.film_id上面的 film 函数就在 premieres 和 films 表之间手动建立了关联关系。rows 1 则表明对于一个确定的输入只有一条返回数据,表明该关联关系是 多对一 关系,SDK返回的结果是 json对象 。
通过 function 手动建立关联关系后,如何在程序中进行关联查询呢,代码写法如下:
const { data, error } = await supabase .from('premieres') .select(` location, film(title) `)上面的代码中,我们可以看到,premieres 是我们要查询的表,原本我们业务逻辑上是要关联 films 表进行关联查询,但是由于两个表之间没有外键关联,无法直接完成关联查询。这里我们在select函数中传入的不再是 films 表,而是 film 函数,该函数返回的是 films 表,所以,PostgREST内部会帮我们做好转换,并成功完成最终的关联查询。
另外提一句,film 这个函数名字可以根据自己的需要命名,并不是因为要关联的表是 films 就必须命名为 film 。
通过上面的函数定义,我们业务上可以实现通过 premieres 表关联 films 表,如果业务需要通过 films 表关联 premieres 表呢,需要额外定义关联关系吗,答案是要。
所以一般,我们需要定义一对 function 双向关联两个表。上面两个表的反向关联定义如下,这是一个一对多的关联关系:
create function premieres(films) returns setof premieres as $$ select * from premieres where film_id = $1.id $$ stable language sql;客户端关联查询代码的写法如下:
const { data, error } = await supabase .from('films') .select(` title, premieres(location) `)像C++/Java等面向对象编程语言一样,function可以重载,以实现用同一个函数名进行多个不同表之间的关联,下面是一个例子:
create function directors(films) returns setof directors rows 1 as $$ select * from directors where id = $1.director_id $$ stable language sql; create function directors(film_schools) returns setof directors as $$ select * from directors where film_school_id = $1.id $$ stable language sql;第一个函数定义了 films->directors 的关联关系,第二个函数定义了 film_schools->directors 的关联关系。PostgREST会自动识别这种重载。重载的好处是,我们可以在编写客户端代码时,对同一个目标表可以使用同一个函数进行关联查询。
上面的例子中,目标表都是 directors ,所以我们在编写客户端代码时不论是 films 还是 film_schools 表要关联该目标表,都可以使用同一个关联函数:
const { data, error } = await supabase .from('films') .select(` title, directors(last_name) `) const { data, error } = await supabase .from('film_schools') .select(` school_name, directors(last_name) `)使用 function 手动构建两个表之间的关联关系时,需要特别注意如下一些约束:
必须使用 SETOF 作为返回结果的定义。如果不使用SETOF,PostgreSQL不会内联这些函数,从而影响性能。
当使用 ROWS 1 来建立 x对一 的关联关系时,要确定function确实只返回一条记录。
关于PostgreSQL的函数内联,可以看一下官方文档的描述。1.2 如何解决递归关联问题
上面我们遗留了一个问题,如果表的外键指向自己,怎么进行关联查询:
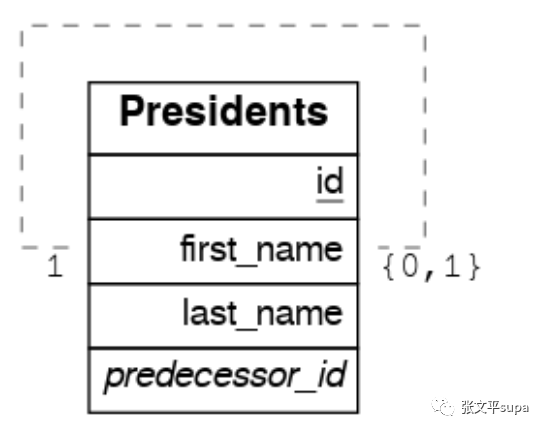
此时我们需要创建一对function 来手动进行关联,可以看到两个函数都是返回rows 1 ,表示两者之间存在一对一关系:
create or replace function predecessor(presidents) returns setof presidents rows 1 as $$ select * from presidents where id = $1.predecessor_id $$ stable language sql; create or replace function successor(presidents) returns setof presidents rows 1 as $$ select * from presidents where predecessor_id = $1.id $$ stable language sql;此时我们如果要查询某位总统的前任和继任者,可以这么写代码:
const { data, error } = await supabase .from('presidents') .select(` last_name, predecessor(last_name), successor(last_name) `) .eq('id', 2)返回结果示例:
[ { "last_name": "Adams", "predecessor": { "last_name": "Washington" }, "successor": { "last_name": "Jefferson" } } ]1.3 如何解决一对多递归关联问题
要创建一对多(多对一)递归关系,下面是一个例子:
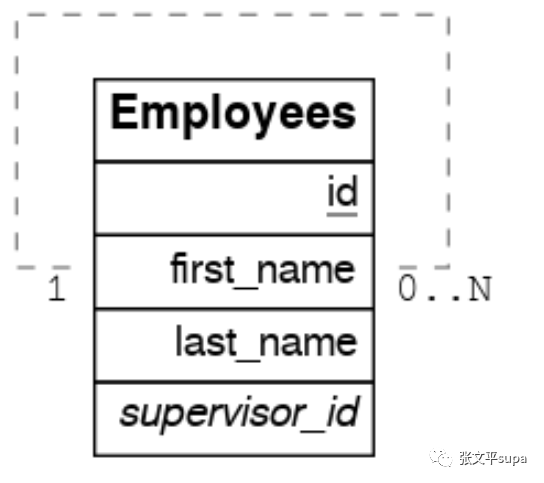
主管和员工是一对多关系,员工和主管之间则是多对一关系,需要创建如下一对 function :create or replace function supervisees(employees) returns setof employees as $$ select * from employees where supervisor_id = $1.id $$ stable language sql; create or replace function supervisor(employees) returns setof employees rows 1 as $$ select * from employees where id = $1.supervisor_id $$ stable language sql;1.4 如何解决多对多递归关联问题
多对多也是一个非常常见的递归关联场景,比如我们常见的微博用户之间互相关注,就是一个非常典型的单表数据多对多关联。上面我们在介绍多对多关联时,我们知道两个表之间无法直接用SQL表达多对多关系,需要有一个额外的关联关系表,对于单表递归场景的多对多也是类似的,要在用户之间构建多对多关系,需要有一个单独的关注(订阅)表:
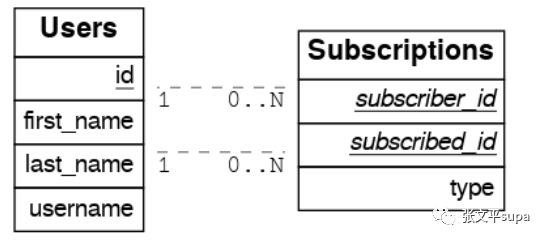
建表语句如下:create table users ( id int primary key generated always as identity, first_name text, last_name text, username text unique ); create table subscriptions ( subscriber_id int references users(id), subscribed_id int references users(id), type text, primary key (subscriber_id, subscribed_id) );为了表达多对多关联查询,这里我们也需要借助 function 的能力:
create or replace function subscribers(users) returns setof users as $$ select u.* from users u, subscriptions s where s.subscriber_id = u.id and s.subscribed_id = $1.id $$ stable language sql; create or replace function following(users) returns setof users as $$ select u.* from users u, subscriptions s where s.subscribed_id = u.id and s.subscriber_id = $1.id $$ stable language sql;subscribers 函数查询出的是用户的粉丝,following 函数查询出的是用户所的关注用户,就好比:
要查询某个用户的粉丝和关注用户,可以如下方式编写代码:const { data, error } = await supabase .from('users') .select(` username, subscribers(username), following(username) `) .eq('id', 2)返回结果示例如下:
[ { "username": "wuershan", "subscribers": [ { "username": "zhangsan" }, { "username": "lisi" } ], "following": [ { "username": "chenmuchi" } ] } ]