小课堂,关联关系与关联查询
-
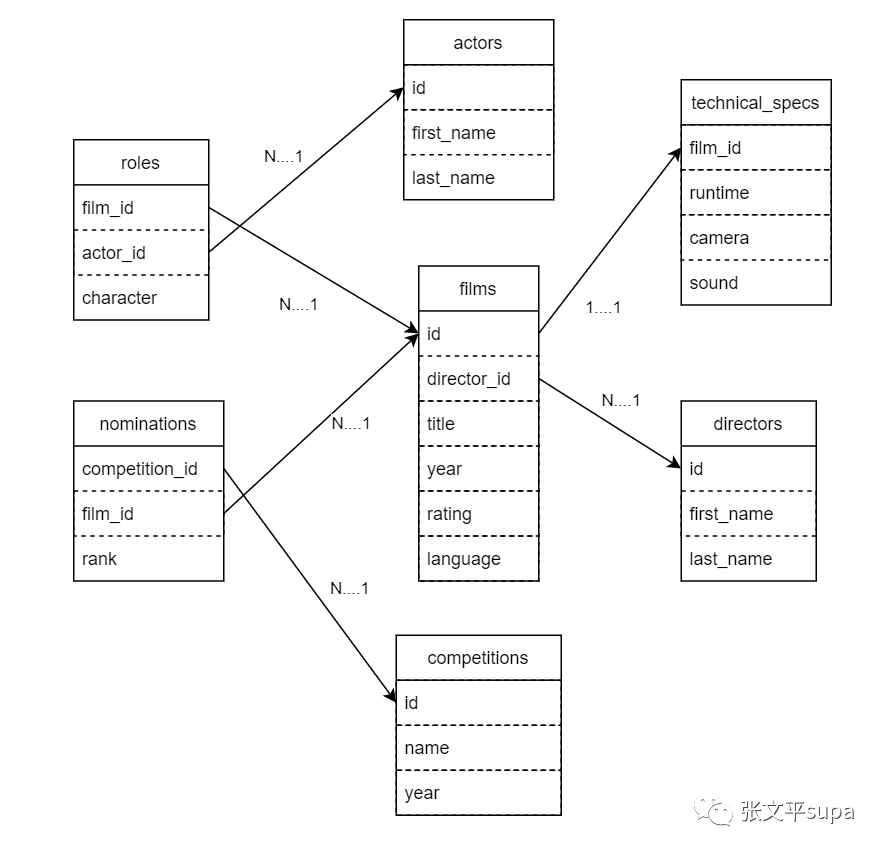
下面是一个简单场景的ER图,来源于PostgREST,该场景描述了电影、导演、演员、角色、技术、提名、竞争对手等表之间的关联关系:
1.1 多对一关系
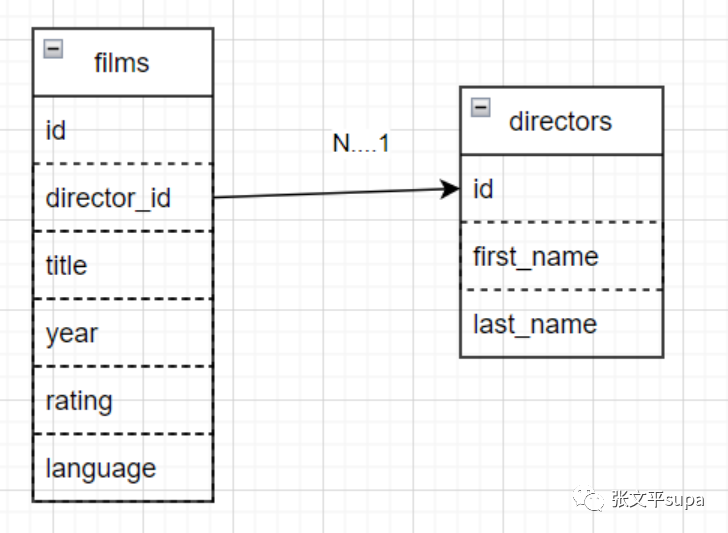
假设多个电影的导演可能是同一个人,但一个电影的导演不能是多个人,那么films表和directors表之间存在多对一关系,可以如下方式建表:
create table directors( id serial primary key, first_name text, last_name text ); create table films( id serial primary key, director_id int references directors(id), title text, year int, rating numeric(3,1), language text );也就是如下图所示的关系:
如果我们要查询所有电影的title以及每部电影的导演名字,可以如下方式进行关联查询:const { data, error } = await supabase .from('films') /* films: 要查询的表 */ .select(` title, directors( last_name ) `)可以看到,主表films作为参数传给了from函数。关联表directors及要查询的字段全部写在select函数中,其中title是films的字段, directors( last_name ) 描述了要从关联表directors取last_name字段。
关联查询的条件为: films.director_id = directors.id,该条件由PostgREST服务自动添加。返回数据的格式如下:
[ { "title": "Workers Leaving The Lumière Factory In Lyon", "directors": { "last_name": "Lumière" } }, { "title": "The Dickson Experimental Sound Film", "directors": { "last_name": "Dickson" } } ]注意,由于是多对一关系,所以返回结果中每一项的directors的值是一个json对象,而不是json数组。
1.2 一对多关系
上述关系反过来 directors->films 就是一对多关系,关联查询方法类似:
const { data, error } = await supabase .from('directors') /* directors: 要查询的表 */ .select(` last_name, films( title ) `)上面的主表变成了directors ,关联表变成了films ,由于是一对多关系,返回结果的films的值变成了json数组:
[ { "last_name": "Lumière", "films": [ {"title": "Workers Leaving The Lumière Factory In Lyon"} ] }, { "last_name": "Dickson", "films": [ {"title": "The Dickson Experimental Sound Film"} ] } ]1.3 多对多关系
多对多关系不能直接在两个表之间用外键约束进行表达,要表达多对多关系,需要一张额外的表,该表需要包含两个外键约束,分别关联到不同的表,本例中,roles表就在films表和actors表之间建立了多对多关系,如下图所示:
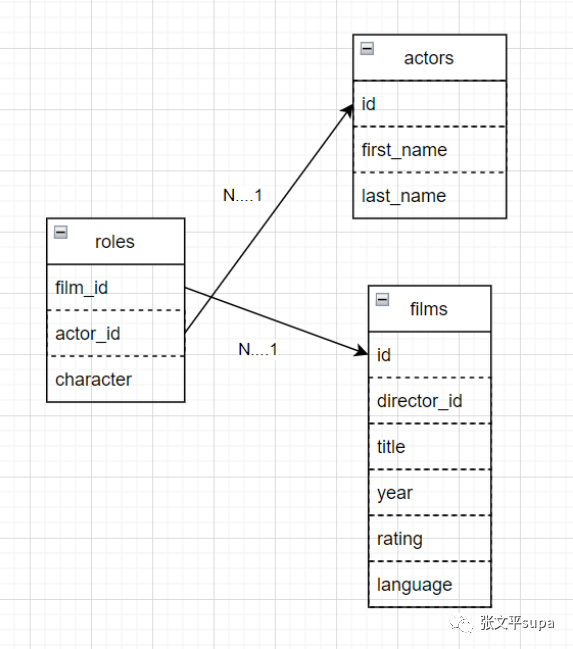
相关建表语句如下:create table actors( id serial primary key, first_name text, last_name text ); create table roles( film_id int references films(id), actor_id int references actors(id), character text, primary key(film_id, actor_id) );roles表有两个外键,分别关联到 films 表和 actors 表,而 films 和 actors 表之间并没有外键关联关系,PostgREST可以识别到这种情况, 因此我们在编写代码时,可以直接关联 films 和 actors 表,他们内部之间如何借助 roles 表完成关联,则由PostgREST在服务端自动完成。
例如:查询所有演员以及其参演的电影,可以如下方式编写代码:
const { data, error } = await supabase .from('actors') /* actors: 要查询的表 */ .select(` first_name, last_name, films( title ) `)1.4 一对一关系
一对一关系表示外键约束的两端在自己的表中都是唯一的,通常对应字段是primary key或者有unique约束,比如:
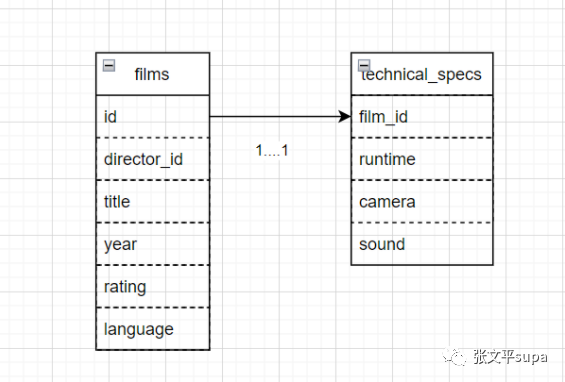
technical_specs 的建表语句如下:CREATE TABLE technical_specs( film_id INT REFERENCES films UNIQUE, runtime TIME, camera TEXT, sound TEXT );film_id 在 technical_specs 表中是唯一的,而 films.id 是 primary key ,也是唯一的,因此这两个表是一对一关系。对于PostgREST来说,只要关联关系的对端是 对一 关系,查询的返回结果的对应值就是 JSON 对象,只要是 对多 关系,查询的返回结果的对应值就是 JSON数组。
当要查询所有电影,以及电影使用的摄像机类型时,可以如下方式进行关联查询:
const { data, error } = await supabase .from('films') /* films: 要查询的表 */ .select(` title, technical_specs( camera ) `)返回结果如下:
[ { "title": "Pulp Fiction", "technical_specs": {"camera": "Arriflex 35-III"} }, ".." ]这一小节介绍了最基本也是最常用的关联查询方法,从上面几个示例可以看到,只要在表与表之间直接或间接建立了外键关联,在编写代码时就可以对这两个表进行关联查询,从多对多的例子中,我们看到客户端代码甚至不需要显示的通过中间表进行关联,PostgREST后台会自动处理好处理,让代码编写变的简单直接。
关联查询的代码编写方法也很简单,主表放在from函数中作为参数,关联表要查询的字段用表名包裹后放到select函数中作为参数即可。
1.5 如果两个表之间存在多个外键关联关系怎么办
像下面这种:
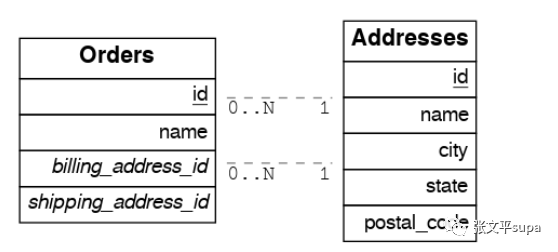
订单表的 billing_address_id 和 shipping_address_id 都跟addresses表有关联关系,此时如果直接对这两个表进行管理查询会报错,类似下面这种错误:
代码:
const { data, error } = await supabase .from('orders') .select(` *, addresses(*) `)返回
{ "code": "PGRST201", "details": [ { "cardinality": "many-to-one", "embedding": "orders with addresses", "relationship": "billing using orders(billing_address_id) and addresses(id)" }, { "cardinality": "many-to-one", "embedding": "orders with addresses", "relationship": "shipping using orders(shipping_address_id) and addresses(id)" } ], "hint": "Try changing 'addresses' to one of the following: 'addresses!billing', 'addresses!shipping'. Find the desired relationship in the 'details' key.", "message": "Could not embed because more than one relationship was found for 'orders' and 'addresses'" }为了正确关联这两个表,需要在建表的时候明确指定外键名称,并在关联查询代码中使用该名称进行关联查询。我们先看一下表定义时如何设置外键名称:
create table addresses ( id serial primary key, name text, city text, state text, postal_code char(5) ); create table orders ( id serial primary key, name text, billing_address_id int, shipping_address_id int, constraint billing foreign key(billing_address_id) references addresses(id), constraint shipping foreign key(shipping_address_id) references addresses(id) );上面的 billing 和 shipping 就是两个外键的名字,如果不指定名称,数据库会为我们生成一个名称,这里为了能让我们准确的控制代码如何编写,手动指定外键约束的名称。
正确的代码写法:
const { data, error } = await supabase .from('orders') .select(` name, billing_address:addresses!billing(name), shipping_address:addresses!shipping(name) `)返回结果:
[ { "name": "Personal Water Filter", "billing_address": { "name": "32 Glenlake Dr.Dearborn, MI 48124" }, "shipping_address": { "name": "30 Glenlake Dr.Dearborn, MI 48124" } } ]同样的,我们也可以根据addresses表来查询有哪些订单是与该地址相关联的:
const { data, error } = await supabase .from('addresses') .select(` name, billing_orders:orders!billing(name), shipping_orders!shipping(name) `) .eq('id', 1)该查询的返回结果示例:
[ { "name": "32 Glenlake Dr.Dearborn, MI 48124", "billing_orders": [ { "name": "Personal Water Filter" }, { "name": "Coffee Machine" } ], "shipping_orders": [ { "name": "Coffee Machine" } ] } ]上面的例子中我们用到了eq过滤条件,后面会介绍。
1.6 递归关联
有一类比较特殊的外键关联关系,就是自己关联自己:
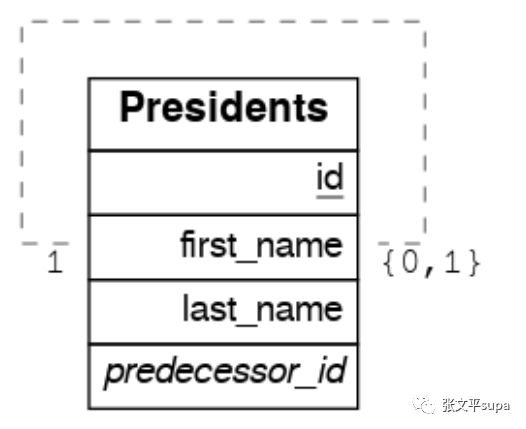
上图中presidents表的predecessor_id指向的是当前表的id字段,这种情况我们称之为递归关联。递归关联要想在客户端代码中执行关联查询,需要依赖 function ,在下一小结介绍完 function 的使用方法之后,我们再回过头来看看这个问题怎么解决。