MemFire教程|FastAPI+MemFire Cloud+LangChain开发ChatGPT应用
-
为什么选择这三个组合
- OpenAI官方SDK是Python,此开发语言首选Python
- FastAPI是Python语言编写的高性能的现代化Web框架
- MemFire Cloud提供向量数据库支持,向量数据库是开发知识库应用的必选项
- MemFire Cloud提供Supabase托管,LangChain原生支持Supabase API
- LangChain是AI应用开发的主流框架,能方便的组合各种AI技术进行应用开发
FastAPI介绍
FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 3.6+ 开发。
关键特性:
- 快速:可与 NodeJS 和 Go 并肩的极高性能(归功于 Starlette 和 Pydantic)。最快的 Python web 框架之一。
- 高效编码:提高功能开发速度约 200% 至 300%。*
- 更少 bug:减少约 40% 的人为(开发者)导致错误。*
- 智能:极佳的编辑器支持。处处皆可自动补全,减少调试时间。
- 简单:设计的易于使用和学习,阅读文档的时间更短。
- 简短:使代码重复最小化。通过不同的参数声明实现丰富功能。bug 更少。
- 健壮:生产可用级别的代码。还有自动生成的交互式文档。
- 标准化:基于(并完全兼容)API 的相关开放标准:OpenAPI (以前被称为 Swagger) 和 JSON Schema。
官方文档:https://fastapi.tiangolo.com/zh/
ChatGPT介绍
准确来说ChatGPT只是openai基于GPT模型开发的一个应用,只不过这个词更流行,更广为人知。对于开发者来说,更准确的说法是GPT模型。目前openai提供的模型包括:
模型 描述 GPT-4 GPT-3.5的优化版本,理解能力和生成自然语言和代码的能力更好。 GPT-3.5 GPT-3的优化版本。 DALL·E 文生图AI模型 Whisper 音频转文本AI模型 Embeddings 文本转向量模型 Moderation 敏感词检测模型,用以检查用户的输入是否合规 每个模型下面又分别有很多细分的模型,在文本和代码生成场景,官方推荐使用两个模型:
gpt-3.5-turboorgpt-4,本文使用目前成本更优的gpt-3.5-turbo。相对应的,gpt-4能理解更复杂的指令,也会尽可能不胡言乱语,但是gpt-4成本要高一些,推理速度要慢一些。GPT模型的应用场景:
- 编写各种类型的文档,包括学术论文
- 生成代码
- 基于知识库进行问题回答
- 分析文本,包括阅读论文、解读代码等都能胜任
- 对话工具,比如客服
- 为软件提供自然语言接口
- 教学导师
- 翻译
- 游戏角色AI
openai的更多资源请参考:
MemFire Cloud介绍
本文主要使用了MemFire Cloud的BaaS服务提供的数据库自动生成API以及向量数据库能力。MemFire Cloud的BaaS服务还提供了其他一些方便开发者进行应用开发的功能:
- 完整的用户注册、登录、权限管理API,web前端和App开发人员可以直接调用,几行代码完成用户注册登录功能。
- 微信小程序、手机短信验证码、github、apple等第三方用户接入支持。
- 最流行的postgres关系数据库支持,自动生成增删查改API接口,支持向量化插件pgvector。
- 提供对象存储接口,方便应用开发者上传下载图片、文档等。
- 静态托管和自定义域名服务,可以让开发者不需要为部署前端代码专门购买云服务器。
- 云函数可以方便处理复杂和敏感的业务逻辑,也可以用来托管完整的api服务。
MemFire Cloud更多信息,请参考:https://memfiredb.com/
GPT初体验
下面是openai官方的一个例子:
import os import openai openai.organization = "org-kjUiGhsu6S3CI2MUch25dMOF" openai.api_key = os.getenv("OPENAI_API_KEY") openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who won the world series in 2020?"}, {"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}, {"role": "user", "content": "Where was it played?"} ] )参数必填项:
- model:模型选择,这里用的是
gpt-3.5-turbo - messages:信息,可以只包含一个问题,也可以包含更多上下文,以帮助AI更准确的回答问题。
AI开发的最主要的工作就是组装合适的messages,以达到更精确的回答用户问题的目的。一条message包含role和content两个元素。其中role包含:
- system:相当于系统设定,一般用来告诉ai他要扮演什么角色,如何回答问题等。
- assistant:辅助信息,帮助AI更好的理解用户的当前问题。通常用于包含多轮对话的上下文信息,也可以用来给出一些问答样例。
- user:用户的提问内容。
FastAPI编写后端服务
如果你使用过FastAPI,可以跳过本节内容。
如果你有flask或django的基础,强烈建议阅读官方的这两个教程,可以帮助你快速了解fastapi的使用方法。
- https://fastapi.tiangolo.com/zh/tutorial/sql-databases/
- https://fastapi.tiangolo.com/zh/tutorial/bigger-applications/
如果你是web服务的新手,建议从头阅读fastapi的教程文档,写的非常好。
https://fastapi.tiangolo.com/zh/tutorial/first-steps/
我们先以上面openai的官方示例,来看一下如何使用fastapi来编写服务端代码,完成与openai的交互,并暴露接口给你的web或app客户端使用。为了方便,我们将所有代码放在一个main.py中演示,如果你要实现一个完整的应用,建议参考大型应用开发这篇教程,模块化组织你的代码。
接口定义
一个简单的可运行的接口定义:
from fastapi import FastAPI app = FastAPI() @app.get("/hello") async def hello(): return {"message": "你好"}安装下列依赖就可以运行了:
# 安装依赖 pip install "uvicorn[standard]==0.23.1" "fastapi[all]==0.99.1" # 运行服务 uvicorn main:app --reload访问接口:
curl http://127.0.0.1:8000/hello封装openai调用接口
了解了fastapi的接口定义方法,我们就能很快将openai的官方示例封装成接口:
from fastapi import FastAPI import openai app = FastAPI() openai.organization = "org-kjUiGhsu6S3CI2MUch25dMOF" openai.api_key = os.getenv("OPENAI_API_KEY") @app.get("/openai") async def openai(): return openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who won the world series in 2020?"}, {"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}, {"role": "user", "content": "Where was it played?"} ] )错误处理
在调用openai的接口时,如果发生错误,openai会抛出异常。在FastAPI的服务代码中,如果我们不处理openai的异常,FastAPI会将异常抛出,并返回客户端500 Internal Server Error。通常我们需要以更结构化的方式将具体的错误信息返回给接口调用者。
FastAPI提供了异常处理的回调接口,以openai的异常为例,可以通过如下方式注册异常处理函数,以更友好、统一的结构返回错误信息:
from fastapi import FastAPI, Request from fastapi.responses import JSONResponse from openai import OpenAIError app = FastAPI() # 捕获异常,并返回JSON格式的错误信息 @app.exception_handler(OpenAIError) async def openai_exception_handler(request: Request, exc: OpenAIError): return JSONResponse( status_code=exc.http_status, content={'code': exc.code, 'message': exc.error}, )了解了FastAPI的api定义方法和错误处理方法,我们基本上可以完成一个简单的web服务程序了。
基于openai开发知识库应用的基本原理
LangChain的文档中对QA场景的AI应用开发有比较具体的讲解,感兴趣的可以深入阅读:
https://python.langchain.com/docs/use_cases/question_answering/
下图是知识库类AI应用的基本开发流程:
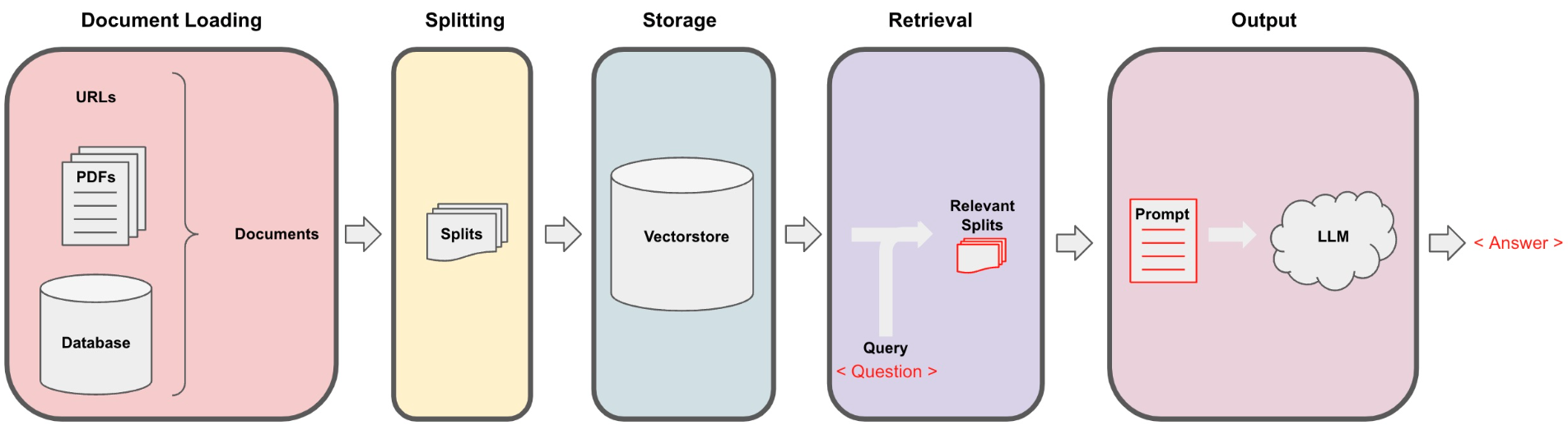
从图中可以看到,大致可以分为如下步骤:
- 文档处理:将pdf、docx、数据库中的数据转换成文本内容。目前openai的chat模型接收的都是文本数据。
- 数据切分:将处理过后的文本内容进行切分。切分的目的是方便语义化检索,让检索内容更精确,另外也是为了适配AI接口的限制。gpt-3.5-turbo的最大tokens数量是4k,gpt-3.5-turbo-16k也只有16k,因此文档切分是必需的步骤。
- 向量化:openai提供了embedding模型,专门用来将文本转换成向量化数据,向量化的目的是方便后续根据用户的输入来检索相似度高的知识。这里就需要用到向量数据库来存储embedding模型的输出。 以上是知识库处理步骤,这一部分通常是运行在应用的后台,需要持续不断的获取最新的知识(比如最新的产品文档、技术手册),并更新向量数据库中的数据。 接下来是用户问答的处理流程:
- 知识检索:将用户的问题向量化,然后到向量化数据库中检索相似度最高的知识(可以根据需要选取相似度高的前n项)。
- AI辅助解答:将检索到的知识以及设定好的prompt信息一起发送给ai模型,ai模型会结合自己已有的知识以及知识库中检索到的知识进行最终的答案生成。
LangChain基本用法
根据上面的流程,我们完全可以自主的实现一个ai应用了,为什么要引入LangChain呢?
如果你通读了LangChain的文档,对于如何借助LangChain完成知识库应用应该有了基本的认识。结合上面的基本原理,我们来看下LangChain能为我们提供哪些能力。
- 数据加载能力 在上面的步骤中,我们首先要完成的是将已有的知识文档处理成文本数据。LangChain目前已经内置类非常多的文档类型处理能力,包括常见的pdf、docx、markdown、html、json、csv等,同时兼容了一百多种数据源,几乎囊括了市面上所有最常用的服务,包括S3、Bilibili、EverNote、Github、Hacker News、Slack、Telegram等等。 下面是加载Web数据的WebBaseLoader的使用方法:
from langchain.document_loaders import WebBaseLoader loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/") data = loader.load()- 数据切分能力 LangChain提供了文本切分工具,可以方便的将加载后的文本进行切分处理。上面将网页内容加载到data对象之后,可以使用RecursiveCharacterTextSplitter进行文本切分:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0) all_splits = text_splitter.split_documents(data)- 向量化能力
LangChain支持常见的向量化数据库以及embedding模型接入能力,以MemFire Cloud托管的SupaBase和openai embedding模型为例(参考):
import os from supabase.client import Client, create_client from langchain.vectorstores import SupabaseVectorStore from langchain.embeddings import OpenAIEmbeddings supabase_url = os.environ.get("SUPABASE_URL") supabase_key = os.environ.get("SUPABASE_SERVICE_KEY") client: Client = create_client(supabase_url, supabase_key) vector_store = SupabaseVectorStore.from_documents( all_splits, OpenAIEmbeddings(), client=client)要使用LangChain + pgvector的向量化数据库能力,需要在MemFire Cloud上创建应用,并开启vector扩展,然后创建documents表和函数。可以使用SQL语句完成这些操作:
-- Enable the pgvector extension to work with embedding vectors create extension vector; -- Create a table to store your documents create table documents ( id bigserial primary key, content text, -- corresponds to Document.pageContent metadata jsonb, -- corresponds to Document.metadata embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed ); CREATE FUNCTION match_documents(query_embedding vector(1536), match_count int) RETURNS TABLE( id uuid, content text, metadata jsonb, -- we return matched vectors to enable maximal marginal relevance searches embedding vector(1536), similarity float) LANGUAGE plpgsql AS $$ # variable_conflict use_column BEGIN RETURN query SELECT id, content, metadata, embedding, 1 -(documents.embedding <=> query_embedding) AS similarity FROM documents ORDER BY documents.embedding <=> query_embedding LIMIT match_count; END; $$;- 知识检索 上面介绍LangChain组合openai embedding 和 pgvector进行向量化处理和存储,LangChain的vectorstore可以直接实现向量化检索功能,将用户的问题转换为最切近的知识库数据:
query = "How to build llm auto agent" matched_docs = vector_store.similarity_search(query)matched_docs就是与用户提问相关性最高的的知识库内容。
接下来就可以将matched_docs + 用户的提问打包提交给AI,让AI帮我们生成最终的答案了。
如何将知识库和用户问题打包提交给openai
在GPT初体验章节,我们已经介绍了GPT接口的使用方法和参数含义,这里我们可以使用assistant角色将我们的知识库打包成messages,然后将用户的问题以user角色打包到messages中,最后调用openai的接口:
messages=[ {"role": "assistant", "content": doc.page_content} for doc in matched_docs ] messages.append({"role": "user", "content": query}) response = openai.ChatCompletion.create("gpt-3.5-turbo", messages=messages)你也可以将文档和问题全部打包成user角色的message,大概的格式:
content = '\n'.join[doc.page_content for doc in matched_docs] content += f'\n问题:{query}' messages=[ {"role": "user", "content": content } ] response = openai.ChatCompletion.create("gpt-3.5-turbo", messages=messages)如何让AI生成更符合预期的结果
我们都知道,ChatGPT有的时候会胡言乱语,一般会发生在GPT模型中没有相关的知识的时候。为了让AI回答的更严谨,我们可以给AI一些明确的指令,比如:
docs = '\n'.join[doc.page_content for doc in matched_docs] content = f"'''{docs}'''" content += f'\n问题:{query}' messages = [ {"role": "system", "content": "我会将文档内容以三引号(''')引起来发送给你,如果你无法从我提供的文档内容中找到答案,请回答:\"我无法找到该问题的答案\"。请使用中文回答问题。"}, {"role": "user", "content": content } ] response = openai.ChatCompletion.create("gpt-3.5-turbo", messages=messages)这里有一份GPT的最佳实践可以参考。
使用MemFire Cloud作为AI的记忆体
openai的GPT模型本身是没有记忆力的,如果我们希望知识库应用能像ChatGPT一样跟使用者进行连续的对话,需要让我们的应用有记忆能力,并将记忆的信息在下一次对话时发送给openai的模型,以便模型了解前面跟用户聊了些什么。
另外openai的接口是有token限制的,当连续对话的内容超出了一次api调用的token限制时,需要压缩历史对话信息。有两种压缩方式:
- 方式1:让openai提炼历史对话的概要信息,然后使用概要信息加最新问题进行问答;
- 方式2:从历史对话中检索与最新问题相关性比较高的内容,发送给openai;
不论哪种方式,你都需要对当前会话的历史数据进行记录:
- 方式1:需要记录不断迭代的摘要信息。因为token数量限制,你不能一次性获得所有历史对话的摘要,因此需要不停的叠加历史摘要和最新对话数据,生成新的摘要并以会话id为标识,记录到数据库中。
- 方式2:需要将历史对话的信息通过embedding模型向量化,要并为每个会话构建上下文知识库索引,检索的时候,只检索当前会话的相似内容。
Supabase SDK提供了非常方便的操作数据库的接口,以下为记录会话历史消息的表以及基本的操作方法:
-- 历史消息表定义 create table history_messages ( id bigserial primary key, session_id text, -- 会话id role text, -- 会话角色(user or ai) message text, -- 会话信息 create_at timestamp default(now()) -- 创建时间 )操作历史消息表的方法:
import os from supabase.client import Client, create_client from langchain.vectorstores import SupabaseVectorStore # 初始化客户端 url = os.environ.get("SUPABASE_URL") key = os.environ.get("SUPABASE_SERVICE_KEY") client: Client = create_client(url, key) # 往会话xxxxx插入一条历史消息 client.table("history_messages").insert({"session_id": "xxxxx", "role": "user", "message": "你好"}).execute() # 查询会话id是xxxxx的所有历史消息 client.table("history_messages").select("*").eq("session_id", "xxxxx").execute()