快速入门|使用MemFire Cloud构建Flutter应用程序,视频讲解,手把手引导入门
https://docs.memfiredb.com/base/example/QuickstartsFlutter.html
A
admin 发布的最佳帖子
-
教程22:快速入门| 使用MemFire Cloud构建Flutter应用程序发布在 MemFireDB培训
-
MemFire技术架构简介发布在 MemFireDB介绍文章
MemFire架构图如下:
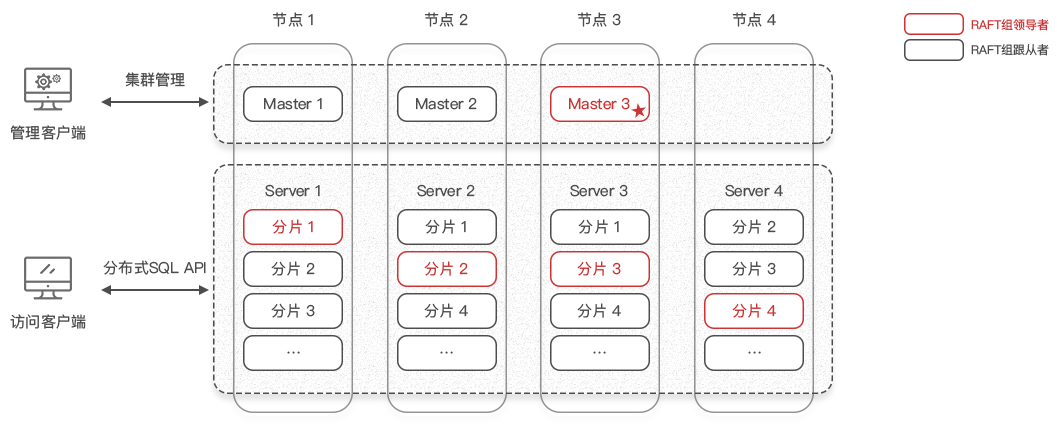
MemFire通过一组节点(可以是VM、物理机器)组成的集群对外提供数据库服务;
MemFire有两组服务:Master和Server,都通过raft提供高可用性支撑;
Master负责存储元数据信息,以及提供数据库的创建、删除等功能;同时负责数据负载均衡控制、Server故障处理等。
Server负责用户数据的存储和访问; -
RE: 作为分布式数据库,MemFire与TiDB有什么区别呢?发布在 MemFireDB用户问答
@moon
TiDB与MemFire都支持功能特性包括:
(1)水平弹性扩展
(2)强一致性的分布式事务
(3)多副本,自动故障恢复
(4)自动故障恢复的高可用两者技术相似:
1、 采用分布式架构
2、 本地存储引擎选择都是RocksDB之上进行改造
3、 受到Google Spanner论文影响;
4、 采用raft协议来保证多副本数据的一致性
5、 两阶段提交(2PC)来保证事务的原子性
6、 MVCC来实现并发访问控制
7、 基于角色的访问控制(RBAC)差异性:
1、MemFire2.1作为OLTP数据库,TiDB产品现在演变为HTAP数据库
TiDB从最开始的OLTP数据库演变为HTAP数据库,推出了TiSpark,应用于大规模OLAP实时分析场景,作为计算引擎;同时为了解决HTAP场景的隔离性,推出了TiFlash组件。
MemFire 2.1目前是作为OLTP数据库,长远发展HTAP数据库。
2、访问接口不同,TiDB兼容MySQL,而MemFire兼容PG -
教程17:应用实战|使用Grafana可视化监控MemFire Cloud数据发布在 MemFireDB培训
应用实战|使用Grafana可视化监控MemFire Cloud数据:https://mp.weixin.qq.com/s/1t6jDHdc1ZMAe_7iu2geWA
-
客户案例 | 政务应急物联网数据中台项目发布在 MemFireDB介绍文章
客户背景
党的十八大以来,中央多次就应急管理工作做出重要指示:要求坚持以防为主、防抗救相结合,全面提升综合防灾能力;坚持生命至上、安全第一,完善安全生产责任制,坚决遏制重特大安全事故。
对新形势新任务新要求,某市应急管理局紧紧抓住应急管理事业改革发展的重大战略机遇,实现了省内生产企业感知监测数据统一接入、物联监测数据本地存储,将汇聚的全省实时传感器数据共享分发给不同的化工园区、地市级别应急管理局,从而帮助各个单位做好安全生产管理工作。同时推进重点危险化学品试点企业开展风险辨识,完成风险分析单元划分、危险源辨识、风险评估等专项工作,制定管控措施并分级管控,形成风险清单,并将双控数据(风险、隐患、排查任务等)上报。通过试点建设,逐步推动全省重点危险化学品企业建立风险分级管控和隐患排查治理双重预防机制。
业务挑战
1、海量数据存储难题。传感器数据类型多、10亿+数据量,单库单表难以存储,且随着时间消逝,容量和数据条数会随之增长。同时,考虑后期接入全省危化企业双控数据,需存储1年以上历史数据。
2、缺乏合规性检查。部分企业未严格按规范操作,上报数据缺少字段,引入问题;
3、统一制定上传程序接口规范文档,并提供给试点危险化学品企业;
4、数据访问控制问题。每个监管单位仅能查看其管理辖区内的数据,不可越权访问。如何进行访问权限管控,保护安全生产企业重要敏感数据。
5、面临性能挑战。海量实时传感器数据,无法直接入库,需进行加工处理,分发,然后写入数据库进行存储并共享。
方案简介
针对客户需求,采用一套3节点的MemFireDB分布式数据库集群存储经过加工处理过的安全生产企业传感器实时和历史数据,并提供标准SQL接口给各个化工园区、地市应急监管单位共享。采用一套3节点的MemFireDB分布式数据库集群作为前置库,存储全省危化企业上传的结构化隐患排查、任务清单数据,并提供标准SQL接口给数据治理调用,进行数据清洗、加工。
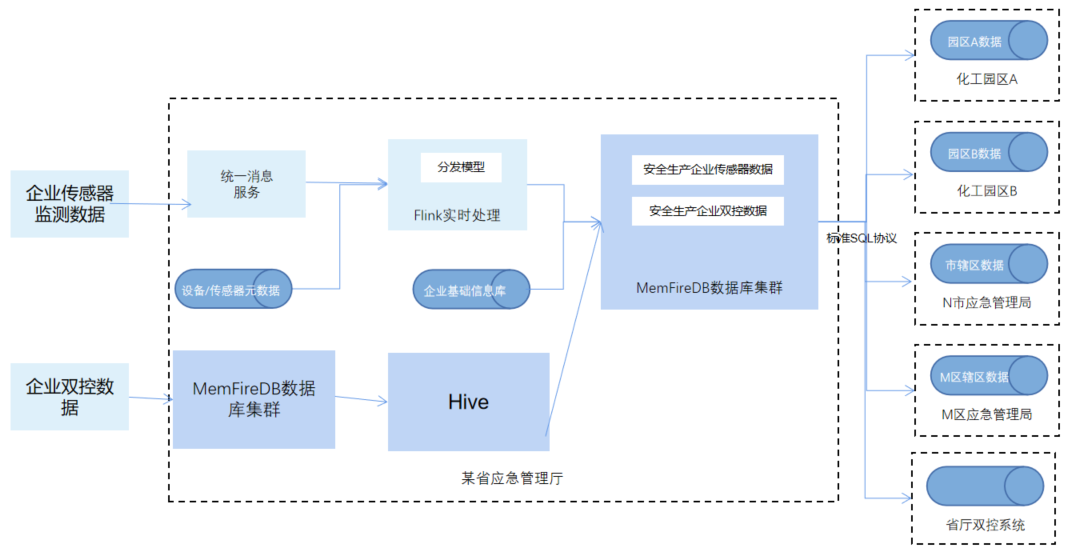
上述方案中,省厅内已汇聚全量的安全生产企业传感器实时数据,并通过统一消息服务组件进行传输。Filnk实时处理引擎利用分发模型+企业基础信息来加工实时传感器数据,并将加工处理后的数据结果存储到MemFireDB数据库。危险化学品企业本地有双控数据库,用来存储隐患排查、任务清单数据,同时使用上报程序,采用统一的数据http接口,将数据上报到省应急管理厅。应急管理厅内部接收程序收到数据,并进行合规性检查,将数据存入MemFireDB数据库中的数据表中,提供标准数据库SQL以便于数据治理抽取库中数据进行清洗、加工,然后结果数据存入MemFireDB集群。
采用MemFireDB数据库集群来存储汇聚的10+亿级别的安全生产企业传感器数据、1+亿级别的双控数据(隐患排查、任务清单数据),采用RBAC方式进行用户访问权限管控,不同监管单位通过不同授权账号和标准的数据库SQL来获取共享的数据,提供历史毫秒级查询、长期存储需求。MemFireDB数据库集群主要存储经过加工分发后的数据,数据副本存储,按需可扩展、任意单节点宕机,业务正常可用。
客户收益
1. 灵活扩展, 降低前期建设成本
统一建设,共享数据资源,降低总体成本。前期采用3节建设规模,避免资源浪费,可支持存储1年的历史数据,支持弹性伸缩,可满足未来业务需求。
2.标准接口,降低开发成本。
MemFireDB提供了标准的数据库SQL接口,与数据治理/其他业务方进行无缝对接,降低开发成本;
3、保障了数据安全性
通过采用基于角色的访问控制(RBAC),授予不同园区/下一级部门权限,保证数据安全可靠。
-
如何下载Windows、Linux、MacOS环境的客户端DbGate发布在 MemFireDB新手区
DbGate是开源免费的数据库客户端,适用于 Windows、Linux、MacOS多种环境,提供强大的功能服务,。
下载地址:https://dbgate.org/
-
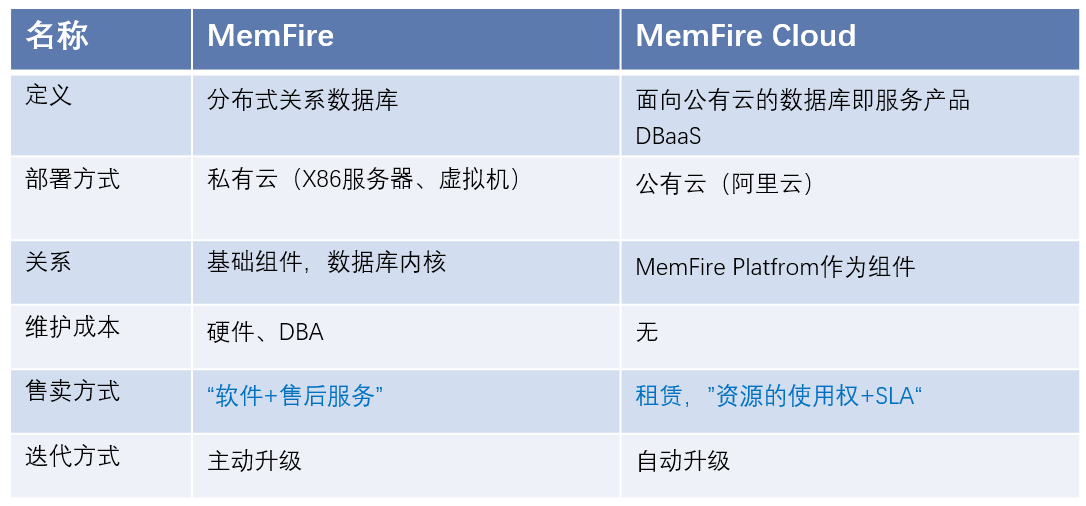
RE: MemFire与MemFire Cloud有什么区别?发布在 MemFireDB用户问答
@小00
MemFire是敏博科技推出的一款高性能、分布式关系型数据库,支持分布式事务,在线平滑弹性伸缩,服务能力线性扩展,跨数据中心部署等能力,可以较好地兼容PostgreSQL的SQL访问形式。
MemFire Cloud是面向公有云的数据库即服务产品,提供自助服务,便捷的管理服务,满足中小企业开发人员对数据库的使用需求;
-
MemFire组网方式介绍发布在 MemFireDB介绍文章
MemFire分布式数据库支持三种组网方式:
1、 MemFire集群采用单节点模式,数据为1副本,这种单节点模式的数据可靠性、服务可用性相对较低,可以采用备份数据防止数据丢失

2、MemFire采用集群模式,Master和Server混合部署,提供高可靠性、可用性服务
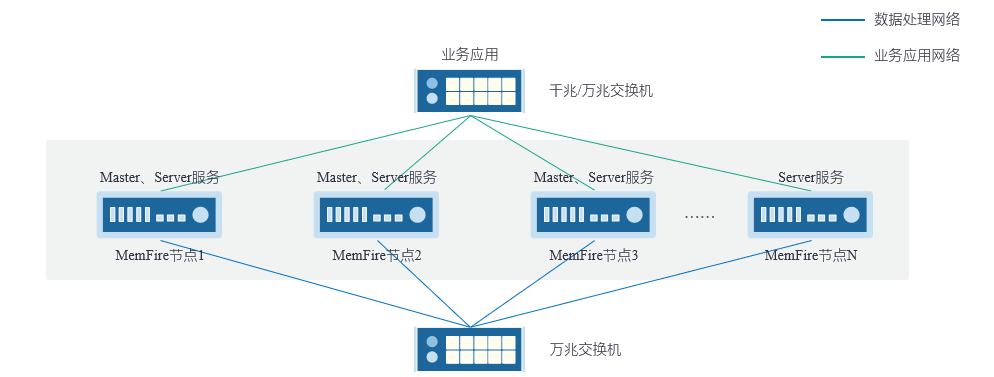
3、MemFire采用集群模式,Master和Server分开部署,提供高可靠性、可用性服务
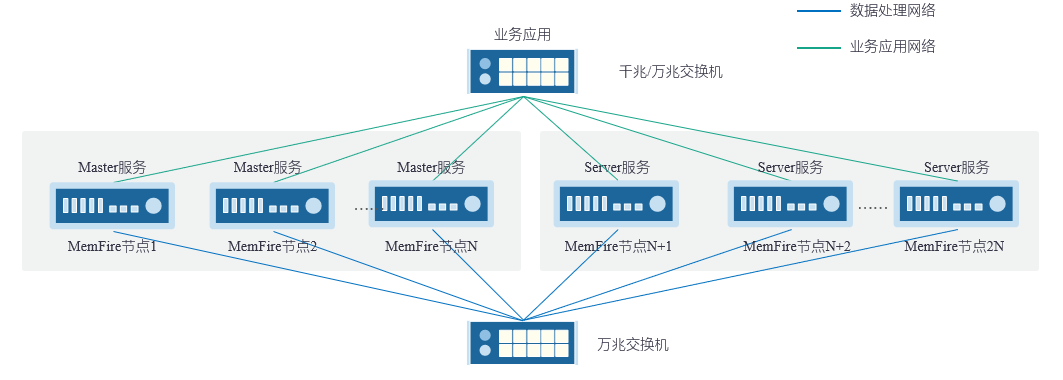
-
MemFire Cloud的客户端工具有哪些?发布在 MemFireDB新手区
MemFire Cloud客户端工具如下:
1、psql客户端,适用于Linux环境,安装命名:yum -y install postgresql11
2、DbGate客户端,适用于 Windows、Linux、MacOS环境,下载地址: https://dbgate.org/
3、dbeaver客户端,适用于 Windows、MacOS环境 下载地址:https://dbeaver.io/files/7.1.0/
4、datagrip客户端,适用于Windows、Linux、MacOS环境,下载地址: https://www.jetbrains.com/datagrip/download/#section=windows
5、Navicat Premium客户端,适用于Windows、Linux、MacOS环境,获取链接:https://pan.baidu.com/s/17r_oHwjeiC6Pqdq2c8yFLQ提取码:s4l7
6、beekeeper-studio客户端,适用于 Windows、Linux、MacOS环境 ,下载地址:https://www.beekeeperstudio.io/get
7、HeidiSQL客户端,适用于Windows环境,下载地址:https://www.heidisql.com/后续越来越多的客户端会陆续加入MemFire Cloud生态,请期待哦~
admin 发布的最新帖子
-
小课堂,Supabase架构介绍发布在 MemFireDB新手区
Supabase基本架构
Supabase围绕PostgreSQL组合了一系列的开源工具,用以实现BaaS所需的用户认证、实时数据库、对象存储、RESTAPI接口等功能。在整合这些工具的同时,为开发者封装了统一的SDK,方便开发者以统一的方式调用这些能力。官方提供了JavaScript和Flutter的SDK,社区贡献了Python、C#、Swift、Kotlin的SDK,开发者在开发移动端和web应用时,可以很方便的调用Supabase提供的后端能力。
下面是Supabase整体架构图:
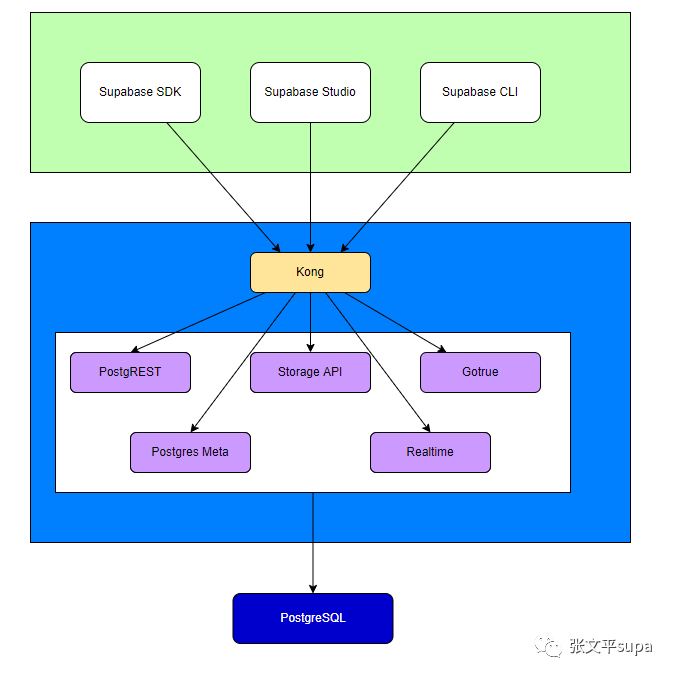
开发者主要通过三个组件来使用Supabase
- Supabase SDK
如上所述,Supabase官方及社区贡献了目前主流的移动端和Web端的SDK,帮助开发者更容易的开发应用。Supabase SDK有非常多的子项目构成,通常以supabase-*命名,如supabase-js,supabase-dart。
- Supabase Studio
Studio是Supabase的管理页面,也就是suapbase的官方网站以及project管理控制台这些Web及后端服务都是Studio这个工具实现的。studio的代码在supabase的主仓库里。
- Supabase CLI
supabase的命令行管理工具,可以方便的在命令行上管理project。
Supabase通过四个核心组件为开发者提供后端服务
- Postgrest
postgres是一个历史比较悠久的开源组件,能够将postgresql以REST接口暴露给开发者,开发者可以直接通过HTTP接口操作数据库。
- storage api
提供对象存储功能,解决开发者需要上传、下载文件的需求,比如图片、文档等。storage api将数据存储在S3存储上。
- gotrue
用户登录认证模块,帮助用户简化其应用的用户管理。允许开发者使用邮箱、手机号进行注册、登录模块的开发,也可以通过OAuth协议接入github、google、apple等平台的账号。
- realtime
realtime利用postgresql的listen/notify机制,实现了postgres数据库实时数据变更通知能力。
在此基础上,Supabase还提供了如下一些能力
- 云函数(edge function)
postgrest本身提供了调用postgresql function的能力,开发者可以在pg中用sql或者JavaScript编写函数,然后通过rpc接口调用pg的函数。pg的函数能在一定程度上解决部分业务场景的需求,但是仍旧存在一些不方便或者不直观的地方。
云函数(edge function)可以更灵活的适配一些场景,比如支付等需要跟第三方系统进行对接的场景,使用云函数可以让开发者编写后端代码并运行在服务端。
- Graphql
graphql是通过postgresql插件实现的,开发者在postgres建表之后,可以直接通过graphql进行数据库操作。
- Web hook
Web hook为开发者提供了事件触发能力,开发者可以设定满足某个条件时,自动触发外部接口的调用,从而跟第三方系统进行集成。比如跟飞书机器人集成。
Supabase还依赖下面这些组件来提供服务
- PostgreSQL
一切的核心。Supabase整个服务是围绕PostgreSQL构建的。
- kong
API网关。负责将API请求路由到目标服务组件,并转发结果给用户。
- postgres-meta
PostgreSQL的元数据管理组件,主要为studio提供服务,可以用来查询数据库中的表、角色,执行SQL等。

